除去特征评分,原始数据素材也包括我们可能关心的内容。或者看板中虽然提供了图表,但我们可能希望批量下载数据。这些场景下,利用Superset提供的sql_lab模块可以直接从底层数据库查询相关的内容。
定制版Superset应用指南系列文档:使用Superset sql_lab
了解sql_lab
sql_lab提供了一个查询界面,可以利用SQL语言访问平台开放的数据库,来进行自定义查询。查询将使用SQL语言,这是一种专门用于操作数据库的语言,本身支持数据的查询、增加、删除、修改。但在sql_lab中,用户的权限受到限制,只被允许使用查询功能。
用户可以参考PostgreSQL的查询语法文档来学习全面的SQL使用方法。
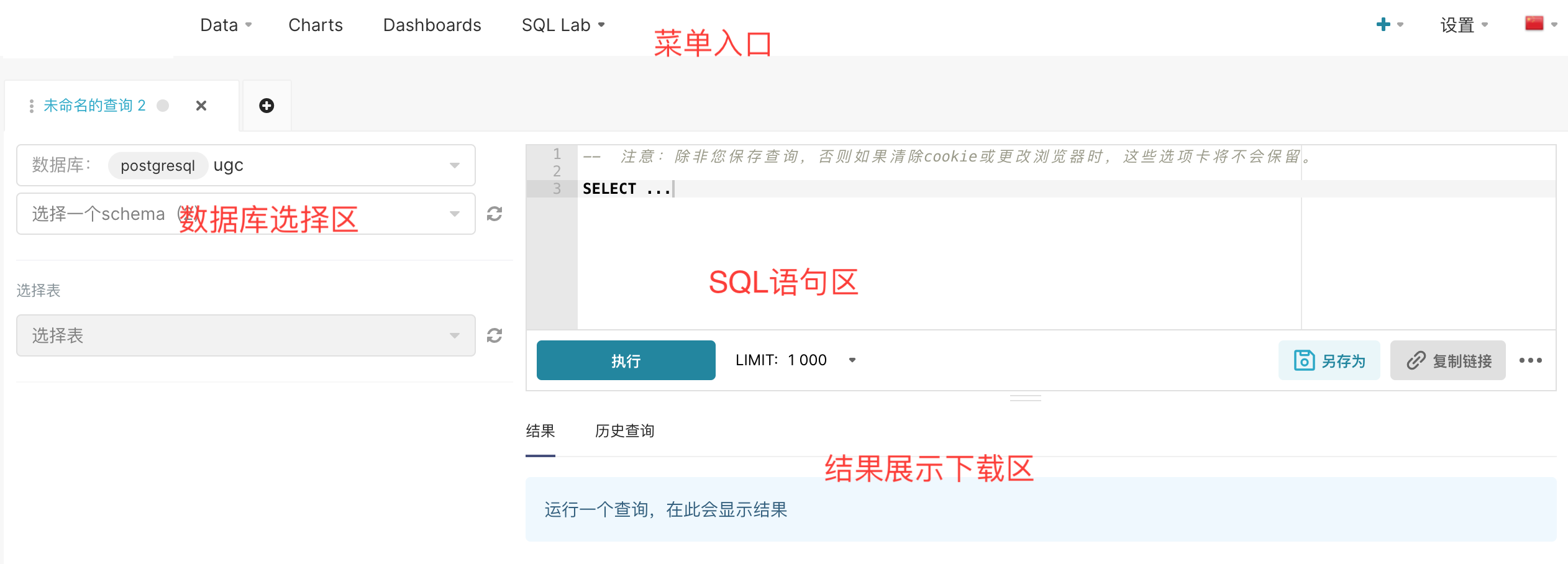
sql_lab模块的操作方式也比较直观,以下将略过界面操作细节,主要通过两个业务场景进行介绍。
场景1 : 寻找包括特定关键词的口碑素材
研究工作中,我们经常希望知道用户在提到某些词汇时都说了什么。这些词汇即使不在特征指标中,我们也仍可以通过查询原始数据来找到内容。
假设我们希望筛选出一些提及“科技感”的文本,以下SQL可以查询到想要的文本。
SELECT
content_id
,content
,model_chn
,car
,post_year
FROM wom_contents_combined w
WHERE
w.content LIKE '%科技感%' -- 更新%号中间的部分更换关键词
;
注意:
- 口碑文本的原始数据在
maxcompute数据库的wom_contents_combined表中 - 包括LIKE的这一行可以用匹配模式筛选包括科技感的文本
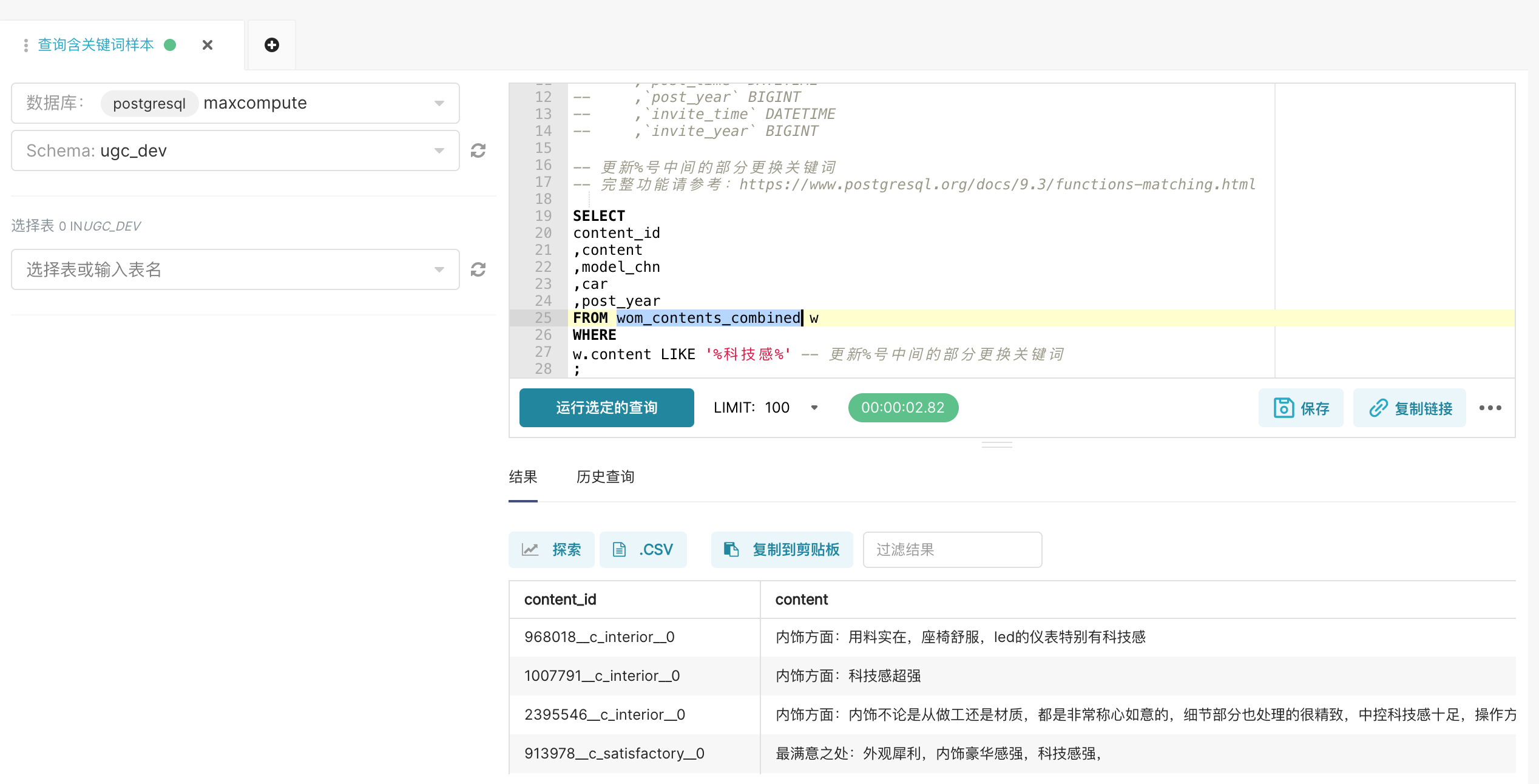
我们还可以利用SQL语句添加额外的条件,进一步聚焦。如仅查询长度大于20个字的内容。
SELECT
content_id
,content
,model_chn
,car
,post_year
FROM wom_contents_combined w
WHERE
w.content LIKE '%科技感%' -- 更新%号中间的部分更换关键词
AND char_length(w.content) > 20 -- 1.增加了内容长度条件
;
注意:
- 增添条件需使用用
AND关键字
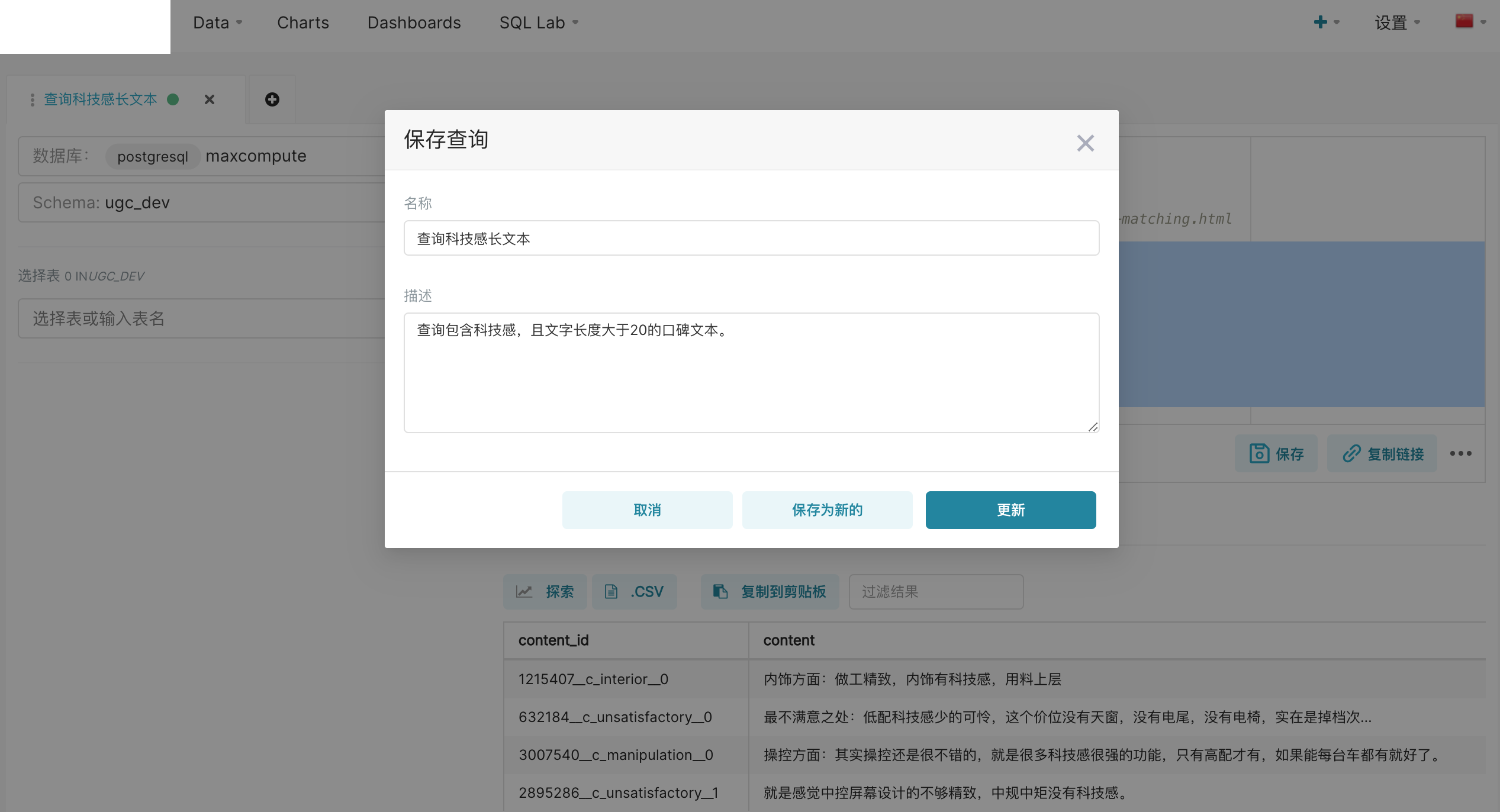
如果经常使用这个查询,我们还可以保存下来,之后可以在已保存查询中找到它。
场景2 : 查询若干车型的全部T3评分
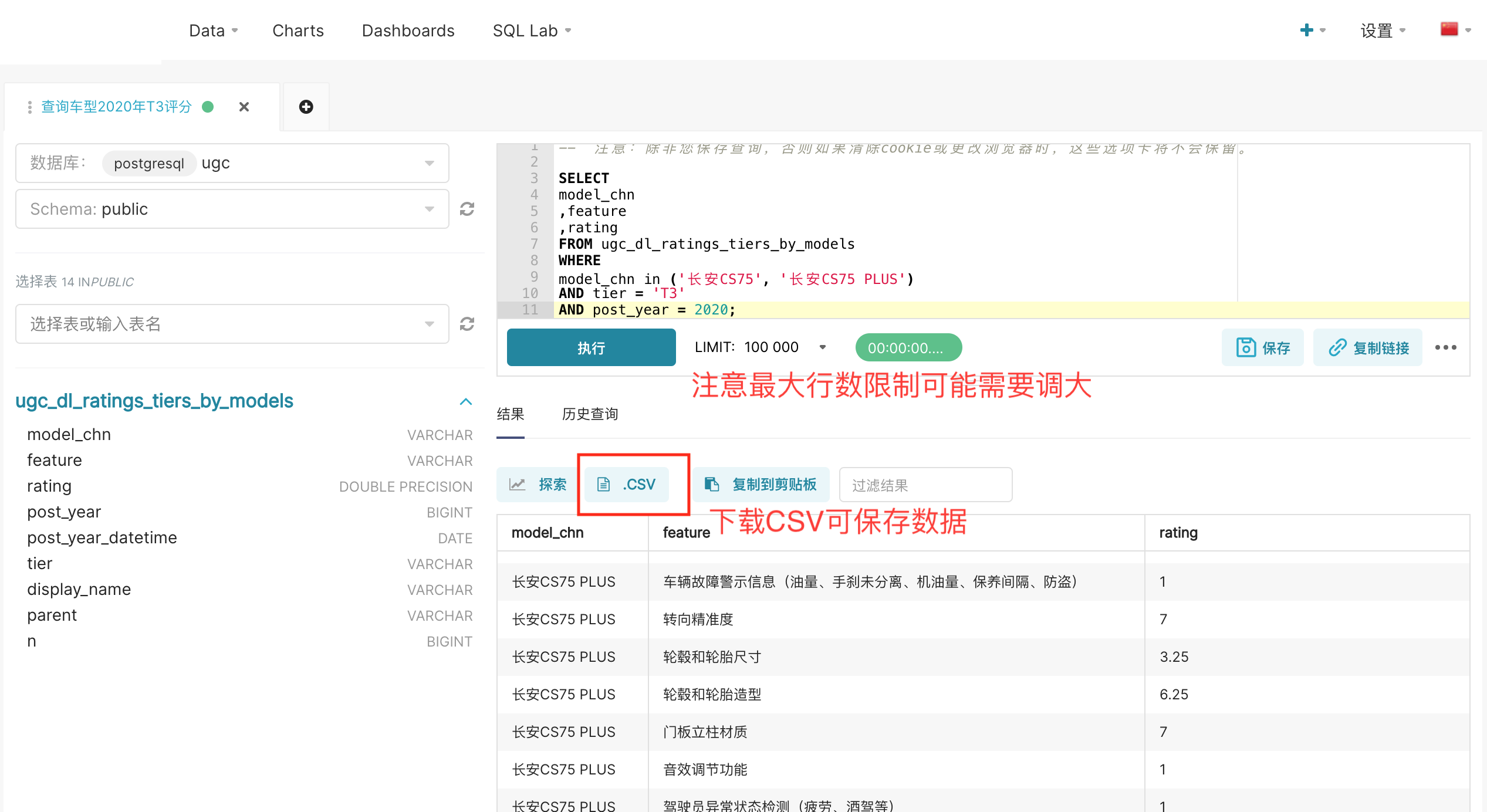
有的时候,我们希望跳过看板探索,直接下载数据。例如,我们希望下载2020年若干车型的全部T3评分。
在sql_lab中可以使用如下语句进行查询。
SELECT
model_chn
,feature
,rating
FROM ugc_dl_ratings_tiers_by_models
WHERE
model_chn in ('长安CS75', '长安CS75 PLUS') -- 需要哪些车型
AND tier = 'T3' -- 哪级指标
AND post_year = 2020; -- 哪一年
继续阅读
sql_lab支持灵活地查询数据,特别是当用户熟悉SQL后更能感受到该模块的便利之处。SQL是数据查询方面最为流行的语言,推荐研究员尽早把它纳入工具箱。
 京公网安备 11011502003050号
京公网安备 11011502003050号